The creation of a comprehensive collections database for Bryn Mawr College’s Art and Artifacts Collections is underway. This extensive, 18-month project is generously funded by the College’s Graduate Group in Archaeology, Classics and History of Art. For the duration of the project, Collections Information Manager Cheryl Klimaszewski (on board as of February 16th) will be assisting collections staff members Emily Croll (Curator and Academic Liaison) and Marianne Weldon (Collections Manager) in the seemingly impossible task of taking 22,000+ records from fourteen different MS Access databases, cleaning them up, and then moving them ever-so-lovingly into EmbARK Collections Manager, a collections information system developed by Gallery Systems. All this, mind you, while also beginning data entry for the additional 40,000 collections objects yet to be cataloged.
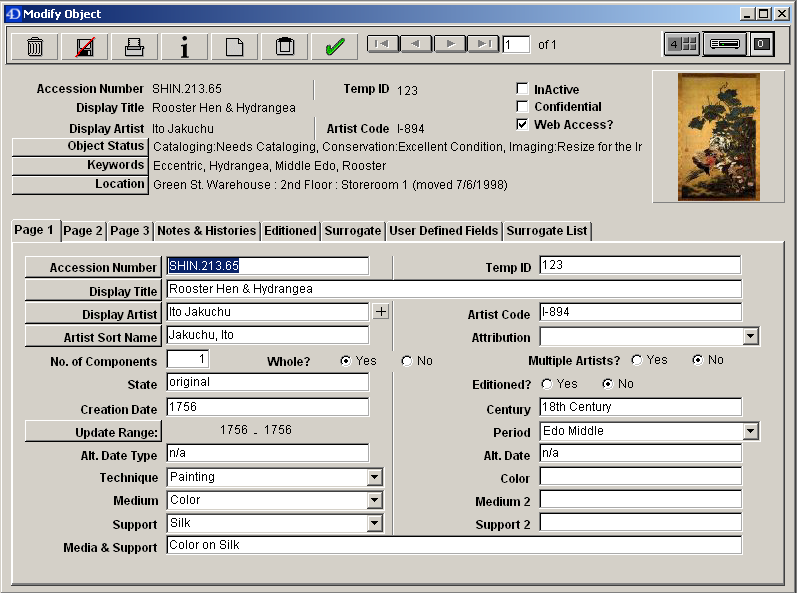
A screen snapshot from the EmbARK Collections Manager demo database.
This project represents a giant leap forward for the Art and Artifacts Collections. Systems like EmbARK are the way to store information about a collection because they employ relational database technology, which provides structured storage, management, and manipulation of data and allows users to interact with data more effectively. Each record in the database acts as a surrogate for the actual item in the collection, so searching the database means (or in our case, will eventually mean) that users have the collection at their fingertips via the database interface.
The creation of digital images of items in the collection is an essential and ongoing part of this project. To date, over 5000 digital images have been created. Students will continue to photograph objects and to digitize existing photographs and negatives.
An important component of our project is the development of data standards, which will govern how collections data is entered into the system going forward. For instance, will we classify “watercolors” as “paintings” or “works on paper”? This is but one simple example of the types of decisions that must be made as to how we conceptualize our collection, and we plan to make such decisions in consultation with members of the BMC community, as appropriate. Such an effort now will pay off in the end: codifying data standards means that data is entered into the database in an orderly, regular, predictable fashion, which will allow for more efficient and meaningful search capabilities once the collection is available on-line. In addition, the standards we develop at BMC will be based on broader museum standards and best practices. This means that, going forward, our data will be more easily adapted as the broader standards continue to develop and improve, opening up the possibility of collaboration between institutions. The bottom line: spending the time to develop strong data standards now will make the collections more accessible to all users and we will never have to tackle a collections data project on this scale again (well, at least not in our lifetimes).
Reviewing current collections data.
So how does one approach such a monumental task? Cheryl has spent her first two weeks reviewing the current databases to learn the answer to the age old question, “What is really going on here?” Multiple Excel spreadsheets now contain composite lists of field names and properties (i.e. how the data in the fields is structured) that have been reviewed and revised to create one master list of field names. This master list will be used to create a final MS Access database into which all the existing records will be merged for further review.
Our to-do list for next week:
- Complete the data merge to the new master Access database.
- Begin review the data as a whole to determine data development priorities for core fields.
- Begin development of data standards for the core fields.
- Begin data cleanup according to those standards, allowing the computer, where possible to do the “heavy lifting” in cleaning up data.