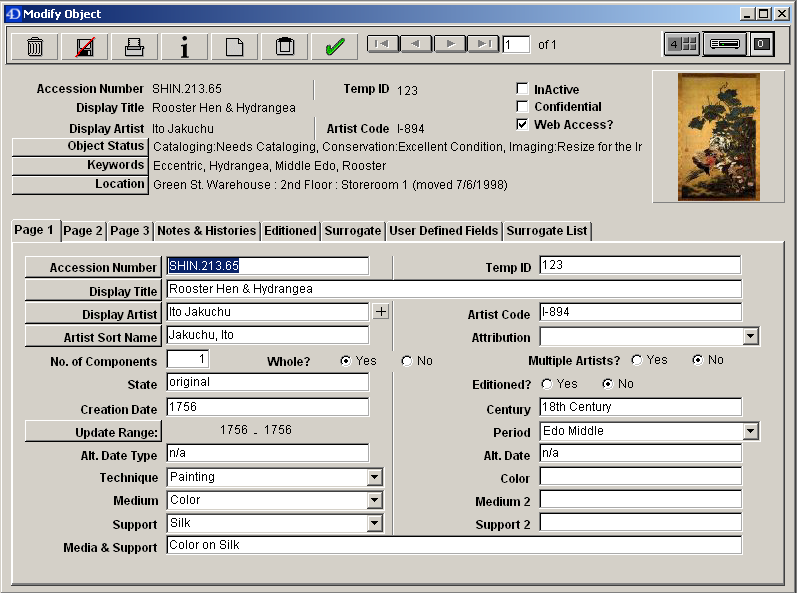
We are happy to report that the server housing EmbARK Collections Manager has been configured and the software has been installed for key users. Collections staff have begun working with the new system on an experimental basis. After several discussions with our EmbARK user support representative, we have also outlined a plan for data migration. The initial phase of data migration should begin in about two weeks, which means that we will have some amount of “real” data in the system in time for our on-site training, which will take place May 4 and 5 on the BMC campus. The training will be attended by staff members from Bryn Mawr, Haverford, and Swarthmore Colleges, along with graduate and undergraduate student employees and interns working with the collections.
Over the next month or so, we will also be meeting with faculty members by department in order to set priorities for developing the database. Faculty assistance will be essential in helping us to identify those collections and objects for which faculty would like to see complete and accurate records (including images) in the database. Though we have been and will continue to “clean up” data in preparation for its move to the new system, this task has so far focused on removing redundant information and generally standardizing existing records on the most general level. Breaking down the collection into smaller, more manageable “chunks” will allow us to create and review object records in detail with the assistance of faculty, staff, and knowledgeable graduate students. As these groups of records are reviewed and finalized, we can begin to turn our attention to our ultimate goal of making this database available to the greater BMC community and, in the long term, to the general public. To this end, faculty assistance is essential in identifying the key objects and parts of the collection upon which to focus our efforts so the collections database can become an accurate and useful research tool for the Tri-College community.